 Fine-Tuning
Fine-Tuning
The Fine-Tuning tool is comprised of two basic functions. Fine-Tuning allows users to adjust any of the built in models used for other Insight and Learning Engine™ (Beta) tools to better fit their data. Full training allows for new learning models to be created. Fine-tuning and full training are accomplished using training data. Training data may be an external source, or generated in Global Mapper using the Generate Training Data option.
|
|
This tool requires Global Mapper Pro |
This tool can be accessed from the Deep Learning (Beta) Drop-down Menu, or from the Deep Learning (Beta) Toolbar.
Due to the heavy processing involved during Fine-Tuning, large files and ground truths may need to be tiled into smaller files before running. This can be accomplished through the Tiling tab in Global Mapper's export dialogs.
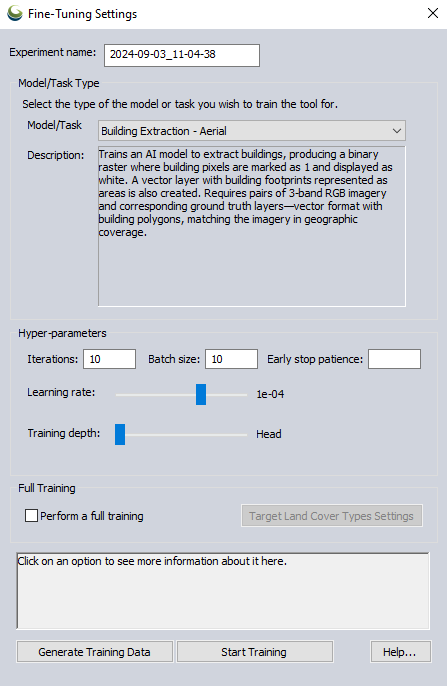
Experiment Name - Specify the name of the output custom training model.
Model/Task Type
The Model/Task drop-down menu can be used to select which type of model to train from the following options:
Building Extraction - Aerial - Train a model to identify and extract buildings using the Object Detection tool from aerial imagery. The training data must include 3 spectral band aerial imagery, and an accompanying layer of vector building footprint area features.
Land Cover Classification (4 band) NAIP - Create a custom model for classifying land cover using the Land Cover Classification tool from 4 spectral band (Red, Green Blue, Near Infrared) NAIP imagery or similar sources. The training data must include 4 band aerial imagery, and a single band or palette land cover reference image.
Land Cover Classification (3 band) NAIP - Create a custom model for classifying land cover using the Land Cover Classification tool from 3 spectral band (Red, Green, Blue) NAIP imagery or similar sources. The training data must include 3 band aerial imagery, and a single band or palette land cover reference image.
Vehicle Detection (3 Bands) - Train a model to identify and extract vehicles using the Object Detection tool from aerial imagery. The training data must include 3-spectral-band aerial imagery and an accompanying layer of vector building footprint area features.
Hyper-Parameters
In a typical workflow, a model should be trained using different combinations of hyper-parameters. When it is time to use the model to make an inference in the Land Cover Classification or Building Extraction Custom Models dialog; information contained in the log file for each separate experiment/trained model can be used to decide which is the best one to choose.
Iterations - Set the number of iterations through the training data. Each iteration represents a complete pass of the training data through the model. Increasing iterations can improve accuracy but extends training duration.
Batch Size - Set the batch size using this parameter. It controls how many examples the model processes simultaneously. Large batch size speeds up training. It is recommended to use even values. The default value is set to the maximum possible that the system's memory can accommodate. Note that actual memory usage may vary during training. If you encounter Out of Memory (OOM) errors, try reducing the Batch Size.
Early Stop Patience - Specify the number of iterations with no improvement after which training will be stopped. Leave this option blank to disable early stopping and train for the full number of iterations.
Learning Rate - Adjust the learning rate with this slider. Moving it to the right increases the rate, influencing how much the model adjusts its predictions with each new batch of training data. Higher rates speed up training but may overshoot optimal solutions.
Training Depth - This slider can be used to adjust the training depth. Moving it to the left increases the number of trainable layers, fine-tuning the model more closely to your data but requiring more training time. This option is deactivated when Perform Full Training is checked.
Full Training
Perform Full Training - Checking this option will specify that a totally new model will be created based on the training data, rather then fine-tuning one of the built in models.
Target Land Cover Type Settings - In this dialog, the target land cover classes used for a full training of a land cover classification model can be specified. A pixel value, class name, color and description for each type can be specified. The resulting classes can be saved to a Land Cover Classification Class Setting File (.gmlcc). An existing Land Cover Classification Class Setting File .gmlcc can also be imported.
Generate Training Data
Selecting this option will allow for training data to be manually created within Global Mapper:
Building Extraction Training Data Generation
With the Building Extraction task selected, the Training Data Generation Options dialog allows for the creation of additional vector building footprint area features . If no vector layer is currently loaded, a blank vector layer can be created for the building footprints to be added to.
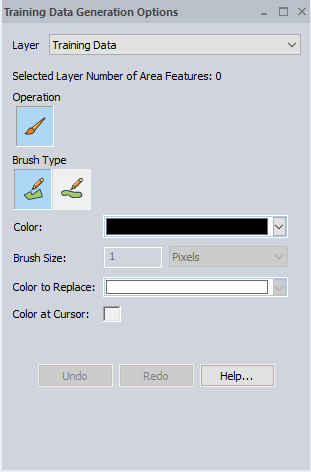
Layer - Specify which layer to add the building footprint area features to. Choose from existing loaded vector layers, creating a new layer, or loading a layer from an existing file.
Brush Type - Choose between Area (Vertex Mode) and Area (Trace Mode) for digitizing the new building footprints.
Land Cover Classification Training Data Generation
With one of the Land Cover Classification tasks selected, the Training Data Generation Options dialog allows for adjustment of the RGB values of a raster image layer that will be used for training. The available actions within the dialog will be similar to those found in the Image Paint Tool.
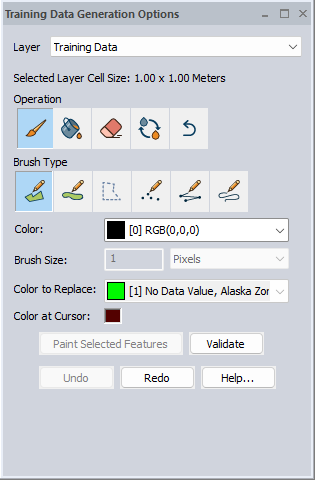
Validate - When using class settings that were loaded from an external .gmlcc file, this button verifies that the applied changes match the target color palette.
When the validation succeeds and displays a green circle, the palette for that layer will be permanently updated to the target palette. This step is important for training with the new palette.
Failing to validate layers before training may cause an "out-of-range values" error during training.
Custom Models
The final output of any training run is a custom AI model. These models can then be used for custom inference on subsequent data sets in the Custom Models tab of the Building Extraction, and Land Cover Classification tools. Information read from the log file of a particular trained model will be displayed within the Custom Models dialog. These values can help make a determination of which model will work best when making an inference.
Once created, Custom Models can be exported, deleted, or imported using the Insight and Learning Engine tab of the Configuration dialog.
After training is complete, users will be prompted to use the trained model for a new inference. If yes is selected, the corresponding tool that the model was trained for (Land Cover Classification, or Building Extraction) will be opened to the Custom Models tab. If no is selected, the trained model will still be retained for future use.
Once created, Custom Models can be download and managed from the Configuration menu.
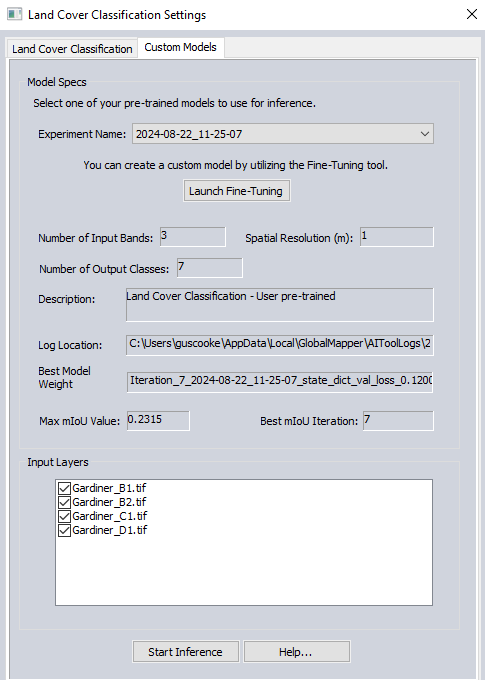
Model Specs
Experiment Name - Use this drop-down menu to select an existing trained models created using the Fine-Tuning tool.
Launch Fine-Tuning - Select this option to open the Fine-Tuning dialog from the Custom Models tab of Land Cover Classification or Object Detection.
Number of Input Bands - This field will display the number of bands of the imagery used to perform the training of that particular model.
Spatial Resolution - The resolution of the imagery used to train the custom model.
Number of Output Classes - This field displays the number of output raster classes the source imagery was divided into.
Log Location- View the location of the saved log for that particular experiment/trained model.
Best Model Weight - This parameter specifies the name of the model which produced the best mIoU value.
Max mIoU Value - The maximum Mean Intersection over Union value achieved for all iterations of the model during that particular experiment is displayed in this field. The mIoU value refers to how closely the results of the trained model overlap with the expected results (or ground truth) that was used for training. For example when training for Building Extraction; a model which resulted in generated polygons having more overlap with the vector area feature layer used to perform the training will have a higher mIoU score.
Best mIoU Iteration - Specifies which iteration of the training data through the model produced the best results based on maximum mIoU value.
Input Layers - Select which loaded compatible layers will be considered during the inference.
Start Inference - Select this option to initiate the inference using the specified custom model.